Introduction
There are a lot of scenario’s where organization are leveraging Azure to process their data at scale. In today’s post I’m going to go through the various pieces that can connect the puzzle for you in such a work flow. Starting from ingesting the data into Azure, and afterwards processing it in a scalable & sustainable manner.
High Level Architecture
As always, let’s start with a high level architecture to discuss what we’ll be discussing today ;
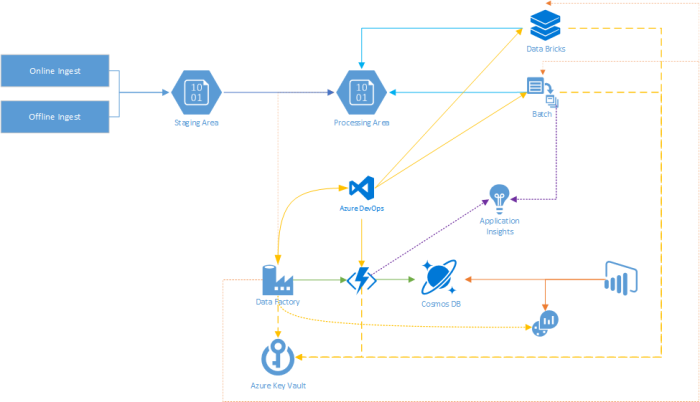
- Ingest : The entire story starts here, where the data is being ingested into Azure. This can be done via an offline transfer (Azure DataBox), or online via (Azure DataBox Edge/Gateway, or using the REST API, AzCopy, …).
- Staging Area : No matter what ingestation method you’re using, the data will end up in a storage location (which we’ll now dub “Staging Area”). From there one we’ll be able to transfer it to it’s “final destination”.
- Processing Area : This is the “final destination” for the ingested content. Why does this differ from the staging area? Cause there are a variety of reasons to put data in another location. Ranging from business rules and the linked conventions (like naming, folder structure, etc), towards more technical reasons like proximity to other systems or spreading the data across different storage accounts/locations.
- Azure Data Factory : This service provides a low/no-code way of modelling out your data workflow & having an awesome way of following up your jobs in operations. It’ll serve as the key orchestrator for all your workflows.
- Azure Functions : Where there are already a good set of activities (“tasks”) available in ADF (Azure Data Factory), the ability to link functions into it extends the possibility for your organization even more. Now you can link your custom business logic right into the workflows.
- Cosmos DB : As you probably want to keep some metadata on your data, we’ll be using Cosmos DB for that one. Where Functions will serve as the front-end API layer to connect to that data.
- Azure Batch & Data Bricks : Both Batch & Data Bricks can be directly called upon from ADF, providing key processing power in your workflows!
- Azure Key Vault : Having secrets lying around & possibly being exposed is never a good idea. Therefor it’s highly recommended to leverage the Key Vault integration for storing your secrets!
- Azure DevOps : Next to the above, we’ll be relying on Azure DevOps as our core CI/CD pipeline and trusted code repository. We can use it to build & deploy our Azure Functions & Batch Applications, as for storing our ADF templates & Data Bricks notebooks.
- Application Insights : Key to any successful application is collecting the much needed telemetry, where Application Insights is more than suited for this task.
- Log Analytics : ADF provides native integration with Log Analytics. This will provide us with an awesome way to take a look at the status of our pipelines & activities.
- PowerBI : In terms of reporting, we’ll be using PowerBI to collect the data that was pumped into Log Analytics and joining it with the metadata from Cosmos DB. Thus providing us with live data on the status of our workflow!
Now let’s take a look at that End-to-End flow!
Staging & Processing Areas
So to start off, let’s take a look at our staging zone ;

Nice and empty as all jobs have been processed, and it was left nicely tidied up! Next to our landing zone, we have a container called “sample” (which will be used later on) containing a data & trigger folder ;

Inside of the data folder, we have one .bag (rosbag format) file (from the Udacit training dataset) ;

In our processing area, we’ll see a container for each of the data (within our predefined boundary, from a business perspective) ;

Where inside of that, we see the “Original” folder, which will contain the data set as it was ingested. Where we have the advantage of being able to push that one to the cold or archive access tier in Azure Storage to reduce the costs. Next to that, we have a folder called “Rosbag”, which contains the extracted content from the rosbag file.

The original ;

The exported data from our rosbag ;

The workflows (pipelines) in Azure Data Factory
In ADF we have several pipelines…

- 00-GenerateIngestWorkload : Every hour, this pipeline will take the sample folder, and use that data to mimmick a new dataset arriving in our staging area.
- 10-IngestNewFiles
- This pipeline will start once a new dataset has arrived in our staging area.
- 11-Initialize : This will create the folder structure linked to our convention. Copy over the files, and delete the files from the staging area once done.
- 12-Convert : This will extract all the data from the rosbag file and put it into the “Rosbag” folder.
- 14-Workbook : This will trigger a DataBricks workbook to be run with the newly arrived dataset.
- …
- This pipeline will start once a new dataset has arrived in our staging area.
For our “00-GenerateIngestWorkload”, we can see there is a trigger called” TriggerEveryHour”

Which will generate a GUID to use for our new dataset ;

And copy the data from the sample location ;

Our “10-IngestNewFiles” will be triggered by “TriggerOnNew…”

Which will basically trigger once a “.done” file has landed in our staging area. This is the convention used in our example to indicate that a data set has finished its ingestation proces.

Let’s take a look at the workflow for our “10-IngestNewFiles” ;

You can see we have our entire business flow modeled out. Where there are even steps calling back to our back-end API (Azure Functions) backed by Cosmos DB (as our Metadata store).

And next to that you see the various more granular/modular pipelines being executed ;
- 11-Initialize

Which takes several parameters and then uses that one to launch a batch job at our Azure Batch account (set to auto-scaling for cost optimization) ;

Where you can see we run the typical Linux commands you are accustomed to ;
In addition, we’re also providing some additional properties from the ADF pipeline ;

Where you can see in the script that we extract that information from the “activity.json” that will be provided along with the batch job. - 12-Convert
 Where the same thing happens for the convert (extraction of the rosbag) one…
Where the same thing happens for the convert (extraction of the rosbag) one… - 13-PII
 Where the PII one runs the Windows commands you are accustomed to, and even a custom built application that was published to batch.
Where the PII one runs the Windows commands you are accustomed to, and even a custom built application that was published to batch. - 14-Workbook
 And then we have our Data Bricks workbook…
And then we have our Data Bricks workbook…

Last but not least, I would just like to point out that this was all done with native integrations from ADF!

The operational side…
Let’s take a look at the dashboards. We can that that there are several pipelines running, and others succeeded ;

When clicking on the “View Activity Runs” icon from the pipeline, we can see a more detailed view of what happened ;

We see that this work flow is currently running the “Convert Rosbag” step ;

Let’s take a look at the “11-Initialize” pipeline for this run. If we click on the “Output”-icon of the activity, we can see a link to the stdout & stderr files ;

Though if we click on them, we cannot reach them without the appropriate security measures. Though let’s copy the job id and check within our Batch Account ;

If we filter on the jobid, we see that job completed ;

And the stdout.txt shows that the job achieved a nice speed whilst copying over the files ;

Now let’s filter on queued & running jobs ;

As this is the “Convert” step in our flow, we see that there is an additional folder in the structure ;

This is actually the folder that’s on the node itself! I know… You do not believe me! Let’s take a look shall we! We browse to the node link on top, and then press “Connect” ;

We generate a temporary user…

Use it to log in to the system, and there it is…

Same view! Live from the node…

Where of course, for this job we can also see the stdout/stderr files (and others) ;

On a not that minor side-note, our pool has a startup task that will prep the nodes to have the necessary packages to execute the required tasks/jobs ;

And likewise for the application packages ;

That workbook thingie…?
Let’s do the same for our “14-Workbook” pipeline ;

And let’s check the details of the workbook activity ;

Where we’ll be shown the link to the job run in Data Bricks (cluster also set to auto-scaling for cost optimization) ;

Let’s click on the link (and login), where we’ll be taken to the output of the job run ;

Where you can see we do a native connection towards Azure Storage from Data Bricks, and process the data… In this case a data set in CSV format ;

Though the same works for the image based data set in there ;

Now let’s do a file system based mount and run our familiar python code ;

Works like a charm!
Reporting?
So we have set up our ADF to send all the metrics & logs to a Log Analytics workspace ;


And that data arrives there… Where there is even a solution pack for this!

In Cosmos DB, we’ll find the metadata that is being created for the drives ;

And we can now connect to these two data sets and create relationships between them to create report of this aggregated dataset!

Closing Thoughts
Even though the posts is very image heavy, it still goes over the various topics in a very fast pace. Though I hope you can see that ADF can serve the role of the orchestrator at hand for your data workflows. From modelling out in a low/no-code manner towards integrating with the various services as shown above. Here you can leverage the power of the cloud (scalability, performance, …), and still keep the code/scripts in a way that is portable outside of Azure. Next to that, having an awesome time to market, and still provide a more than decent dashboard for your operations team. They can go from the pipeline, down to the service called upon… Even logging into the node at the back-end, simulating the error on that machine, and providing the fix back to the production flow.

Karim – Do you have a repo where you put all the script you use for this demo?
Check out this one ; https://github.com/kvaes/TasmanianTraders-Pattern-ADF_Batch_Storage