Introduction
Today’s post is about a story many people have probably heard me telling “in real life”… Where with this I took the opportunity to finally publish it on this blog. 😉 In our DevOps literature we have often used the concept of “Pets versus Cattle” to indicate why go for DevOps. Though in my humble opinion, the focus has always been around tactical and sometimes even framed a bit too harsh. So with this, I hope you enjoy to read my personal version on it!
Real Life Based
Something that not all people might now, but I actually live in… what I sometimes unrespect fully coin … “The Middle of Nowhere”. This being that I life in a more rural municipality in Belgian terms. Where I actually recently moved in the same municipality, my previous residence was actually next to “a farmer”. And to be more precise, a dairy farmer with several hundred cows. His family was hard working 7 days out of the week. Lovely folks too, every time being greeted with awesome hospitality.

Our family itself has also never been a stranger to animals. As we have two mini pigs, two rabbits, three cats … and probably provide food for the entire region worth of birds. The thing that always struck me, was that both of our families loved our animals very much so! Though we both catered to their needs in a different manner. Our were pets… and we had the luxury to spend more time (budget even…) per animal itself. Though that did not mean that our farmer neighbors did not care about their animals. Though let us be honest, with several hundred of cows, you needed to spend your time wisely. Though the animals did not fell short of anything. At the end of they, they were also providing the living hood for this family.
The Difference
As you can already notice, the difference in volume of animals requires a different approach. At the end of the day, they require LOTs of automation to keep everything operational. This goes from preparing food, to feeding, to cleaning, to milking, … to ventilation, to rotating shifts on the fields, etc, etc. Almost everything, except from how little cows come into the world 😉 … was being automated.

Currently I am in the IT industry for more than 20 years already. When I started out we had a mainframe with direct cables to the terminals. The world evolved, and we got physical wintel alike servers… Desktops / workstations surfaced at the desks of everyone in the company. After a while those physical servers got virtualized, and server applications went from a monolith to three tier architecture. After which containers popped up, and also brought microservices to life.
At the end of the day… we went from a technology landscape with a modest amount of machinery… to an overly complex one with A LOT of cogwheels that need to keep on turning!
Automation
Now let us translate this one for the typical enterprises. Each and every one out there has gone through the same evolutions. Some at a different pace then others… Though we can all say that our IT landscapes have become very complex, and have a lot of cogwheels turning. At that point, one cannot do things with the same manual care! This is the point where automation has become a necessity.
In my role I have encountered organizations, who are maintaining multiple thousands of servers… and who still do their upgrade process pretty much manually. They typically counter that they have automated installs in place, though they must admit that the lifecycle to go through this is still pretty much manual. One of those organizations, has at least two FTEs continuously upgrading their machinery, and where they always lag about two majors versions behind on their OS. Simply cause they cannot keep up… And if you discuss deep down with them, they realize that their issue is not increasing on automation. Which in turn, does not help them with creating the value that would be needed for their organization!
Devops?
So what about DevOps? DevOps for me has always been around the automation. How can you increase the throughput of things? How can we drive that lap faster? How can we detect (and fix) errors faster?
And in doing so, I do not even want to discuss the technologies that can enable you here, or what implementations can help. At the end of the day, whatever technology choices you make, it is evolving around increasing the efficiency. About 10 years ago, I presented a session at Experts Live on End-to-End automation. It included the following visualization ;
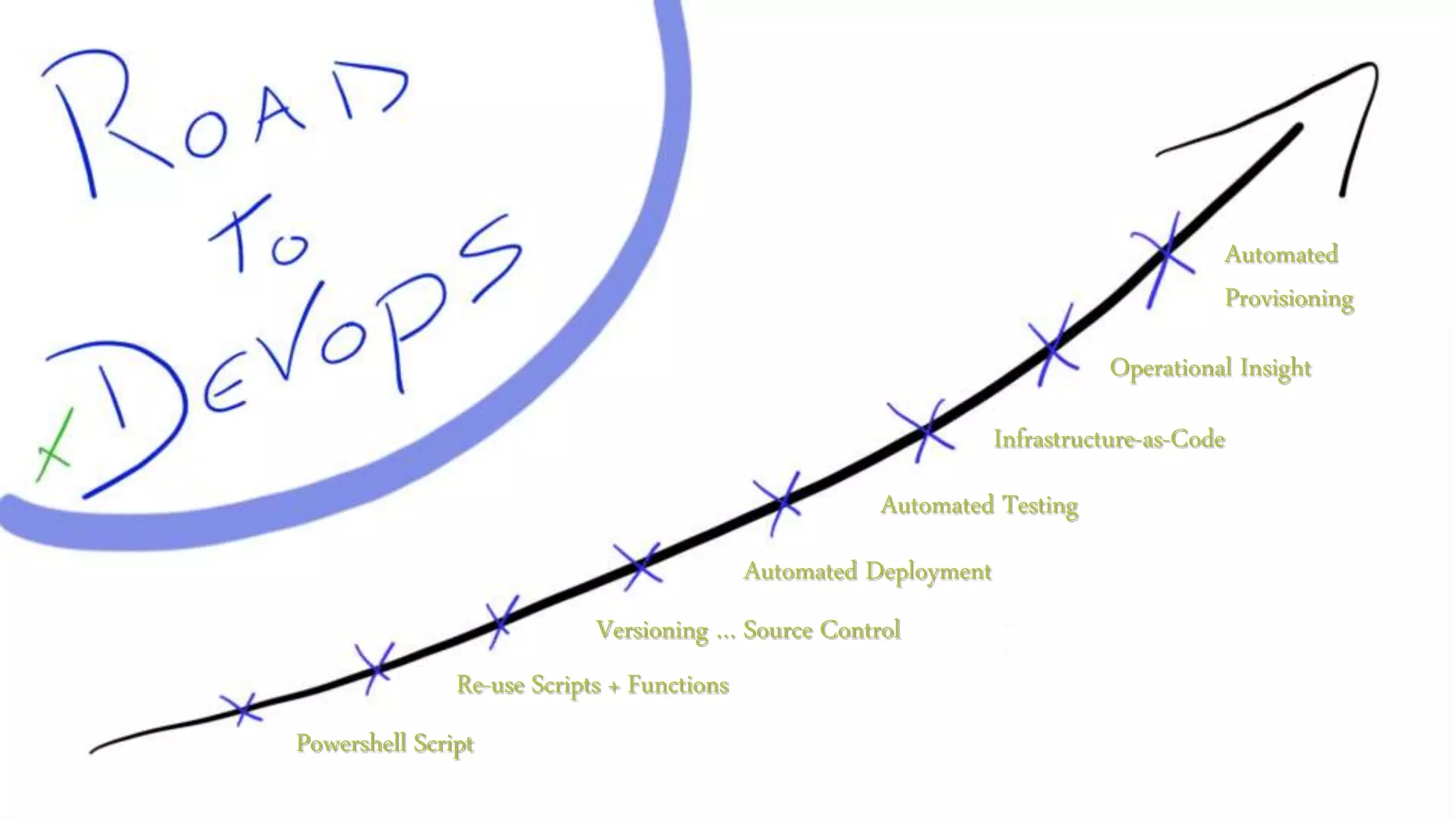
See it more as an inspirational roadmap… and now think this is about 10 years old… How far is your organization along on this? As I personally cannot fathom that people still want to reside on manual actions. They are slow and error prone, and we have the tools now to do these things quite “easily”. I know… things are never easy in IT. Though trust me when I say, that in 2005, when we did the above with shell scripts and without any off the shelve tooling, it was really hard. Though at that time, the organization I worked in (a manufacturing organization) already heavily relied on automation to increase our efficiency when refactoring away from mainframe and onto our custom built ERP.
Closing
As always, I hope these posts help you in your daily life… That it provides insights & value. My personal opinion is that in IT we should look towards near full automation. The technology stacks are enabling us in that direction, and we should not accept the drawbacks of manual actions anymore.
When you are thinking that you are able to do so. Also start thinking why you have not already? Why are you being limited here? Focus on removing those barriers. As in a lot of cases, it is cargo cult that is blocking you here.









