Introduction
Storage Spaces is a technology in Windows and Windows Server that enables you to virtualize storage by grouping industry-standard disks into storage pools, and then creating virtual disks called storage spaces from the available capacity in the storage pools.
For me… Storage spaces is a disruptor in the Enterprise landscape. After the mainframe, we went towards intel hardware. The systems had their own disks and we used them as a stand-alone or did some cloning/copying between them. As the data center grew, this became unmanageable, and we turned towards SAN systems. Here we had several challengers over the years, though the concepts remained the same. At a given point, I was hoping VMware would turn towards the concept that Nutanix eventually released upon the world. Server hardware with direct attached storage, and replication via the virtualization host. 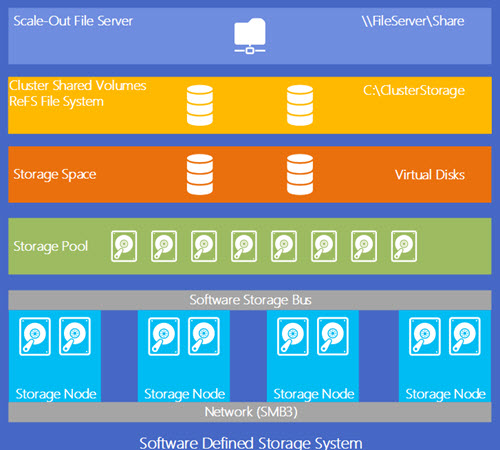 Anyhow, the aspect of using JBOD storage with basic enterprise SAN features excites me! This could provide a lot of IT departments with some budget space to maneuver again… Though, a san is commonly still a single point of failure, so a kind of scale-out concept (instead of a typical SAN scale up!) would be great. And with storage spaces direct, Microsoft has hit the nail dead on for me! Hyper Convergence vs Convergence With the Storage Spaces in Windows 2012 we got a basic NAS functionality; raid0/raid1/raid5, snapshots, pooling. With 2012 R2, the game was on… Storage Tiering, Data Deduplication, flexible Resilience (“Dynamic Hot Spare”) & Persistent Write-back cache. Suddenly, the game was on. Microsoft had turned the vision of SMB as a file server towards a NAS (kinda like Netapp for Linux/VMware). And with the scale-out file server (SOFS), you pretty much had a basic SAN that covered the basic needs of the majority of the SME landschape.
Anyhow, the aspect of using JBOD storage with basic enterprise SAN features excites me! This could provide a lot of IT departments with some budget space to maneuver again… Though, a san is commonly still a single point of failure, so a kind of scale-out concept (instead of a typical SAN scale up!) would be great. And with storage spaces direct, Microsoft has hit the nail dead on for me! Hyper Convergence vs Convergence With the Storage Spaces in Windows 2012 we got a basic NAS functionality; raid0/raid1/raid5, snapshots, pooling. With 2012 R2, the game was on… Storage Tiering, Data Deduplication, flexible Resilience (“Dynamic Hot Spare”) & Persistent Write-back cache. Suddenly, the game was on. Microsoft had turned the vision of SMB as a file server towards a NAS (kinda like Netapp for Linux/VMware). And with the scale-out file server (SOFS), you pretty much had a basic SAN that covered the basic needs of the majority of the SME landschape. ![2015-05-22 13_31_45-MDC-B218.pptx [Protected View] - PowerPoint](https://kvaes.files.wordpress.com/2015/05/2015-05-22-13_31_45-mdc-b218-pptx-protected-view-powerpoint.png) Though, as you can see, the architecture was still comparable towards the “SAN”-architectures we see a lot in the field. The concept that Nutanix brought to life wasn’t there yet. Though, at Microsoft Ignite, Storage Spaces Direct (“S2D”) was announced. And along with it, the possible to go towards a hyper-converged architecture. At that point, a lot of people tweeted ; “Nutanix their stock is less worth after Ignite”. And to be honest, there lies a lot of truth in those tweets… You are now able to build the same kind of Hyper Converged architecture with Microsoft components.
Though, as you can see, the architecture was still comparable towards the “SAN”-architectures we see a lot in the field. The concept that Nutanix brought to life wasn’t there yet. Though, at Microsoft Ignite, Storage Spaces Direct (“S2D”) was announced. And along with it, the possible to go towards a hyper-converged architecture. At that point, a lot of people tweeted ; “Nutanix their stock is less worth after Ignite”. And to be honest, there lies a lot of truth in those tweets… You are now able to build the same kind of Hyper Converged architecture with Microsoft components.  With S2D, you have to conceptual options ;
With S2D, you have to conceptual options ;
- Hyper Converged – “Nutanix Mode” – Scale out with storage & CPU power combined.
- Converged / Disaggregated – “Traditional Mode” – Scale out with SOFS & Compute nodes separately.
For the entry tier segment, this technology step is huge. Twitter has been buzzing about the fact that features like replication are part of the data center edition. Though for me, the hyper-converged part solves this. And let’s be honest… we all know the R&D money needs to come from somewhere, and in the next edition it’ll go towards the standard edition. Storage Replica So what drives the “Hyper Converged”-engine? Storage replication…  Source : https://msdn.microsoft.com/en-us/library/mt126183.aspx The replication comes in the two traditional modes ;
Source : https://msdn.microsoft.com/en-us/library/mt126183.aspx The replication comes in the two traditional modes ;
- Synchronous Replication – Synchronous replication guarantees that the application writes data to two locations at once before completion of the IO. This replication is more suitable for mission critical data, as it requires network and storage investments, as well as a risk of degraded application performance. Synchronous replication is suitable for both HA and DR solutions. When application writes occur on the source data copy, the originating storage does not acknowledge the IO immediately. Instead, those data changes replicate to the remote destination copy and return an acknowledgement. Only then does the application receive the IO acknowledgment. This ensures constant synchronization of the remote site with the source site, in effect extending storage IOs across the network. In the event of a source site failure, applications can failover to the remote site and resume their operations with assurance of zero data loss.
- Asynchronous Replication – Contrarily, asynchronous replication means that when the application writes data, that data replicates to the remote site without immediate acknowledgment guarantees. This mode allows faster response time to the application as well as a DR solution that works geographically. When the application writes data, the replication engine captures the write and immediately acknowledges to the application. The captured data then replicates to the remote location. The remote node processes the copy of the data and lazily acknowledges back to the source copy. Since replication performance is no longer in the application IO path, the remote site’s responsiveness and distance are less important factors. There is risk of data loss if the source data is lost and the destination copy of the data was still in buffer without leaving the source. With its higher than zero RPO, asynchronous replication is less suitable for HA solutions like Failover Clusters, as they are designed for continuous operation with redundancy and no loss of data.
In addition, technet states the following ;
The Microsoft implementation of asynchronous replication is different from most. Most industry implementations of asynchronous replication rely on snapshot-based replication, where periodic differential transfers move to the other node and merge. SR asynchronous replication operates just like synchronous replication, except that it removes the requirement for a serialized synchronous acknowledgment from the destination. This means that SR theoretically has a lower RPO as it continuously replicates. However, this also means it relies on internal application consistency guarantees rather than using snapshots to force consistency in application files. SR guarantees crash consistency in all replication modes
When reading the above… On a conceptual level, this is to be compared with the implementation of Netapp “near online sync”. Anyhow, very cool stuff from Microsoft as this is really entering the SAN market space and understanding the necessities it entails. Another important note ;
The destination volume is not accessible while replicating. When you configure replication, the destination volume dismounts, making it inaccessible to any writes by users or visible in typical interfaces like File Explorer. Block-level replication technologies are incompatible with allowing access to the destination target’s mounted file system in a volume; NTFS and ReFS do not support users writing data to the volume while blocks change underneath them.
From a technical stance, this is completely understandable. Though, do not expect to have “local” access to all data when doing “hyper convergence”. So you will need a high-speed / low latency network between your hyper-converged nodes! Think towards RDMA with infiniband/iWarp… Eager for more?
- Technet Storage Spaces Basics
- Storage Spaces Survival Guide
- Storage Replica Overview
- Storage Spaces Deep Dive
- Aidan Finn’s Blog
- Storage Spaces Direct on Technet
- Windows Catalog – Storage Spaces
- Dell Storage Spaces: An End-to-End Solution
- Deploying Windows Server® 2012 R2 Storage Spaces on Dell PowerVault™ MD1200 and MD1220
- DataOn & Storage Spaces
